

画像生成AIを使っていて「文字が崩れる」「同じ顔ばかりになる」と悩んだ経験はありませんか。
Alibabaが2026年4月1日~3日にかけてリリースした「Wan 2.7」は、AI自身が構図を論理的に計画する「Thinking Mode(思考モード)」を搭載しました。
本記事では、日本語テキストに完全対応し、動画生成まで一気通貫で行える次世代AIの全貌を徹底解説します。
Wan 2.7が生成AIの歴史を変える理由
結論から申し上げます。Wan 2.7は、プロのクリエイターが抱えていた「AIの制御不能な部分」を完全に克服した画期的なツールです。
これまでの生成AIは、プロンプト(指示文)を入力すると、確率に基づいて瞬時に画像を出力していました。しかし、この仕組みには限界がありました。複雑な構図を指定したり、日本語の文字を正確に配置したりすることが非常に困難だったのです。あなたも、AIが生成した看板の文字が意味不明な記号になってしまい、がっかりした経験があるのではないでしょうか。
Wan 2.7は、この根本的な課題を「Thinking Mode(思考モード)」という新技術で解決しました。
AIがすぐに絵を描き始めるのではなく、まずプロンプトの意味を深く理解します。そして、画面のどこに何を配置すべきかを論理的に計画してから、最終的な出力を生成するのです。
この「考えてから描く」というアプローチにより、以下のような圧倒的なメリットが生まれました。
- 空間的なエラーの激減:人物の指が6本になったり、背景の遠近法が狂ったりする問題が大幅に減少します。
- 正確なテキスト描画:日本語を含む12言語のテキストを、指定した場所に正確にレンダリングできます。
- キャラクターの一貫性:同じ人物を異なる角度や表情で描いても、別人のようになりません。
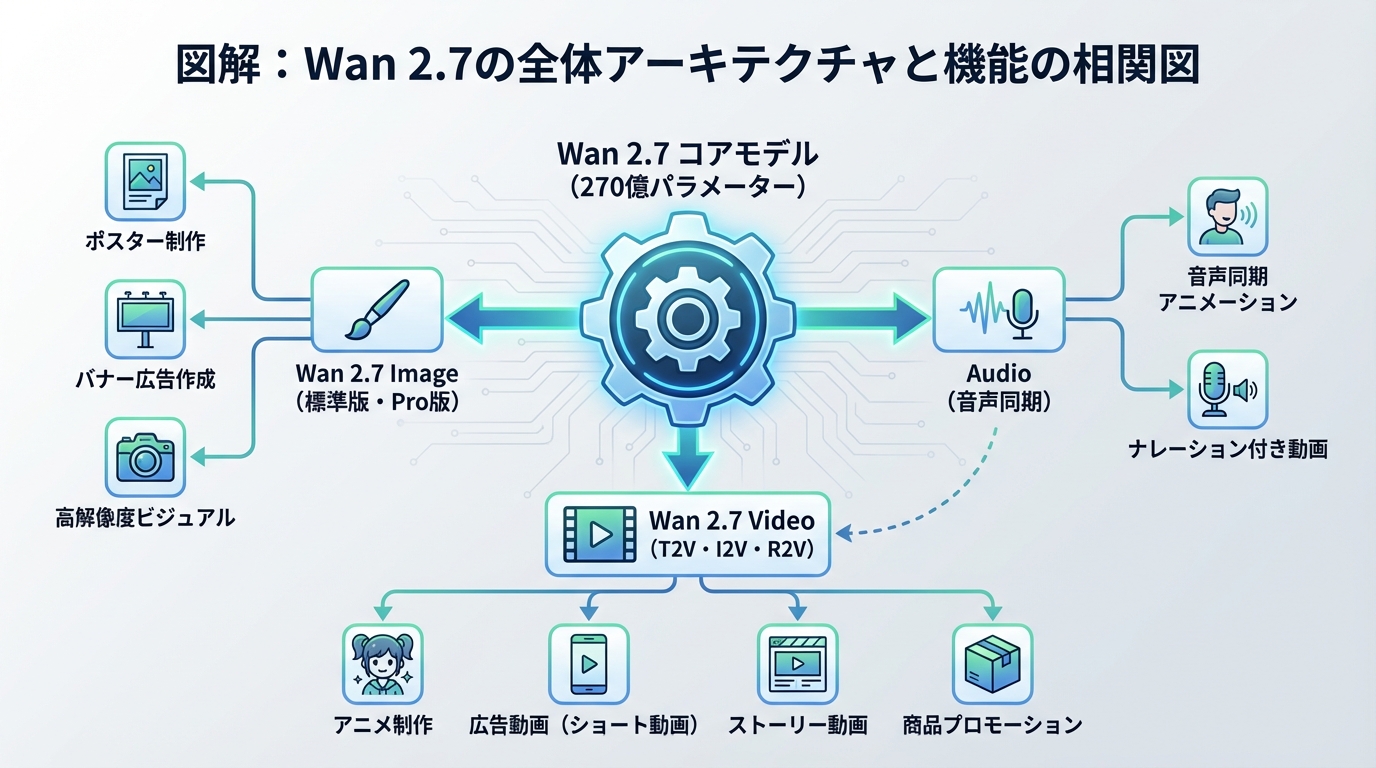
さらに、Wan 2.7は画像だけでなく、高品質な動画生成(Video / I2V)機能も統合しています。静止画から動画への変換、音声の同期、カメラワークの制御まで、すべてを一つのプラットフォームで完結できるのです。
「AIは便利だが、仕事で使うには修正の手間がかかりすぎる」と感じていた方にこそ、Wan 2.7は最適な解決策となります。次世代の生成AIがどのような進化を遂げたのか、その詳細を順を追って見ていきましょう。
Wan 2.7とは?Alibabaが開発した次世代AIの全貌
結論として、Wan 2.7は画像と動画の生成を高度なレベルで統合した、マルチモーダル(複合的な情報を扱える)生成プラットフォームです。
Alibaba(アリババ)の研究機関であるTongyi Lab(通義実験室)は、長年にわたりAI技術の研究開発をリードしてきました。その集大成とも言えるフラッグシップシリーズが「Wan(万象/Wanxiang)」です。
2026年4月1日~3日にかけて正式リリースされた最新版のWan 2.7は、世界中のクリエイターから熱狂的な支持を集めています。
開発背景とTongyi Labの狙い
Tongyi LabがWan 2.7を開発した最大の目的は、「商用利用に耐えうるプロフェッショナルグレードのAI」を提供することです。
趣味でAI画像を楽しむユーザーとは異なり、広告代理店やアニメ制作会社などのプロフェッショナルは、極めて高い精度を求めます。クライアントのブランドカラーを正確に再現し、指定されたキャッチコピーを一言一句違わずに配置しなければなりません。従来のAIモデルは、こうした厳密な要求に応えることができませんでした。
そこでTongyi Labは、約270億という膨大なパラメーター(AIの脳のシナプスの数のようなもの)を持つ巨大なモデルを構築しました。これにより、AIの理解力と表現力が飛躍的に向上したのです。
拡散モデルとFlow Matchingアーキテクチャの融合
Wan 2.7の圧倒的な性能を支えているのは、「Diffusion Transformer(拡散トランスフォーマー)」と「Flow Matching(フロー・マッチング)」という最新のAIアーキテクチャです。
少し専門的な話になりますが、分かりやすく解説します。拡散モデルとは、ノイズ(砂嵐のような画像)から徐々に意味のある画像を浮かび上がらせる技術です。一方、トランスフォーマーは、文章の文脈を深く理解する技術として知られています。Wan 2.7はこれらを組み合わせることで、複雑なプロンプトを正確に画像へと変換します。
さらに、Flow Matching技術を採用したことで、動画生成時の「時間的な整合性」が劇的に向上しました。動画の1フレーム目から最後のフレームまで、キャラクターの服装や背景の細部がブレることなく、滑らかに連続する映像を作り出せるのです。
これらの技術革新により、Wan 2.7は単なる「お絵かきツール」から「プロフェッショナル向けのクリエイティブ・スイート」へと進化を遂げました。
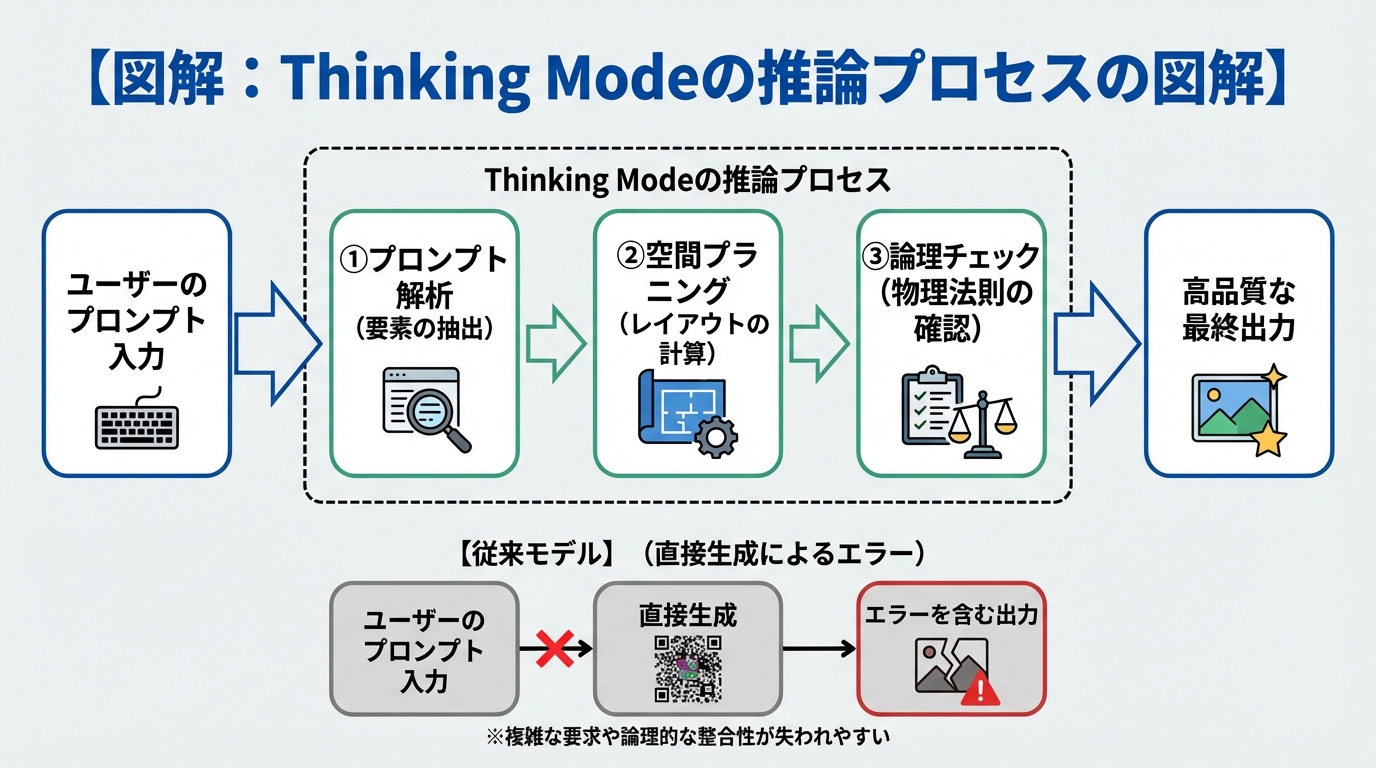
最大の革新「Thinking Mode(思考モード)」の仕組みと効果
結論から言えば、Wan 2.7の最も注目すべき機能は、AIが構図を論理的に組み立てる「Thinking Mode」です。
この機能は、商用利用可能な画像生成モデルとしては世界で初めて搭載されました。従来のAIが抱えていた多くの弱点を、根本から解決する画期的なアプローチです。
Chain-of-Thought(思考の連鎖)推論レイヤーとは
Thinking Modeの中核を担うのが、「Chain-of-Thought(思考の連鎖)」と呼ばれる推論レイヤーです。
人間の画家が絵を描くプロセスを想像してみてください。いきなりキャンバスの隅から細部を描き始める人はいません。まず全体の構図を考え、ラフスケッチを描き、光の当たる方向を決め、最後に細部を仕上げていきます。
Wan 2.7のThinking Modeは、まさにこの人間の思考プロセスを模倣しています。
- プロンプトの解析:ユーザーの指示文から、重要な要素(人物、背景、テキストなど)を抽出します。
- 空間のプラニング:画面内のどこに各要素を配置するのが最も美しいか、レイアウトを計算します。
- 論理的なチェック:「人物の前に机があるなら、人物の足は隠れるはずだ」といった物理法則や論理性を確認します。
- 最終レンダリング:計画に基づいて、高精細な画像を生成します。
この「思考の連鎖」を挟むことで、AIは行き当たりばったりの生成を避け、一貫性のある完成度の高い作品を生み出せるのです。
従来のAIモデルが抱えていた「空間的エラー」の解決
Thinking Modeの恩恵を最も受けるのが、複雑な構図の生成です。
これまでのAIモデルでは、「カフェのテーブルでコーヒーを飲む女性。背景には窓があり、窓の外にはエッフェル塔が見える」といったプロンプトを入力すると、高確率で空間的エラーが発生しました。エッフェル塔がカフェの店内にあったり、コーヒーカップが宙に浮いたりする現象です。
あなたも、こうしたAIの「勘違い」に悩まされた経験があるのではないでしょうか。何度もプロンプトを書き直し、ガチャを回すように生成を繰り返すのは、非常に非効率です。
Wan 2.7のThinking Modeは、空間の奥行きや物体同士の位置関係を正確に把握します。そのため、複数の要素が複雑に絡み合うシーンでも、破綻のない自然な構図を一発で生成できる確率が飛躍的に高まりました。
Wan 2.7 Image(画像生成)の圧倒的な機能と特徴
結論として、Wan 2.7 Imageは、色指定からキャラクター制御まで、クリエイターが求めるあらゆる調整機能を備えています。
画像生成の分野において、Wan 2.7は単に「綺麗な絵が描ける」というレベルを超えました。プロの現場で即戦力となる、高度な制御機能を多数搭載しています。
標準版とPro版の違いと使い分け
Wan 2.7の画像生成には、用途に合わせて「標準版」と「Pro版(wan-2.7-image-pro)」の2つのラインが用意されています。
- 標準版(Wan 2.7 Image):
最大2K(2048×2048ピクセル)の解像度に対応しています。生成速度が速く、柔軟なアスペクト比(縦横比)を指定できるため、SNS用の画像作成や、アイデア出しのためのラフスケッチ生成に最適です。 - Pro版(wan-2.7-image-pro):
2026年4月1日に正式リリースされた高品質版です。最大4K(4096×4096ピクセル)の超高解像度出力に対応し、前述の「Thinking Mode」をフル活用できます。印刷用のポスターや、細部までこだわり抜きたいメインビジュアルの制作に威力を発揮します。
用途に応じてこれらを使い分けることで、コストと時間のバランスを最適化できます。
Thousand-Face Realism(千面写実性)による「同じ顔」問題の解消
AI画像生成の大きな悩みの種が、「どの人物を生成しても同じような顔になってしまう」という問題でした。いわゆる「AI顔」と呼ばれる現象です。
Wan 2.7は、「Thousand-Face Realism(千面写実性)」という機能でこの課題を克服しました。顔の骨格、目元のディテール、肌の質感など、人物のユニークな特徴をピクセルレベルで制御できます。
これにより、多様な人種、年齢、表情を持つ、個性豊かなキャラクターを生成することが可能になりました。広告のターゲット層に合わせた親しみやすいモデルや、物語の主人公にふさわしい特徴的な顔立ちを、自由自在にデザインできるのです。
Precise Color Control(正確な色制御)とブランド表現
企業のマーケティングにおいて、ブランドカラーの正確な再現は絶対条件です。
従来のAIモデルで「コーポレートカラーの青」を指定しても、毎回微妙に異なる青色が出力されてしまい、実務では使い物になりませんでした。
Wan 2.7は、「Precise Color Control(正確な色制御)」機能を搭載しています。プロンプト内で「HEXコード(例:#0055A4)」や特定のカラーパレットを指定することで、ブランドガイドラインに完全に一致する正確なビジュアルを生成できます。
この機能により、AI生成画像をそのまま企業の公式広告やパッケージデザインに採用するハードルが大きく下がりました。
高度な複数参照編集と画像セット生成
さらに実用的なのが、複数の参照画像を用いた編集機能です。
Wan 2.7では、最大9枚の参照画像をアップロードし、それらを組み合わせて新しい画像を生成できます。例えば、「商品の写真」「背景の風景写真」「ライティングの参考画像」の3枚を読み込ませ、「この商品を、この風景の中で、この光の当たり方で描いて」と指示することが可能です。
また、1回の指示で最大12枚の関連する画像セットを生成する機能もあります。
- 同じキャラクターが四季折々の風景にいる様子
- 一つの商品を様々な角度から撮影したカタログ写真
- 映像制作のためのストーリーボード(絵コンテ)
これらを一度に生成できるため、作業効率が劇的に向上します。
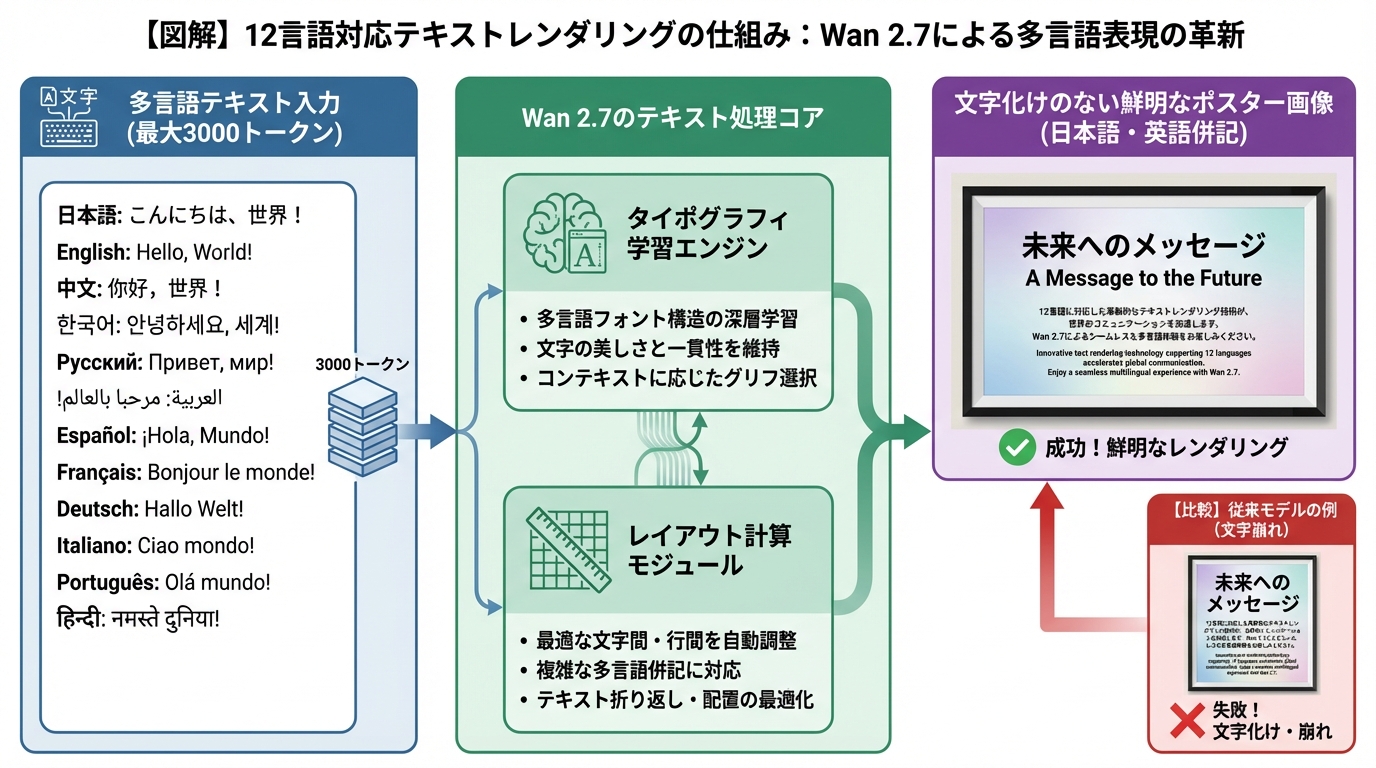
【日本市場向け最重要】12言語対応のテキストレンダリング
結論から申し上げますと、Wan 2.7は日本語テキストの描画において、業界最高水準の精度を誇ります。
日本のクリエイターにとって、Wan 2.7最大のニュースは間違いなくこの「テキストレンダリング機能」です。「12言語対応の日本語生成AI」が、ついに実用レベルに到達しました。
3,000トークン以上の長文テキストを処理する仕組み
これまでの画像生成AIは、文字を描くのが非常に苦手でした。英語の短い単語ならなんとか描けても、長文になるとスペルミスが頻発し、日本語に至っては意味不明な象形文字のようになってしまうのが常識でした。
Wan 2.7は、テキストレンダリングにおいて大きなブレークスルーを果たしました。最大3,000トークン(一般的な文章で数ページ分に相当)という膨大なテキスト入力を処理できる能力を備えています。
中国語、英語、日本語、韓国語、フランス語、ドイツ語、スペイン語など、主要な12言語をサポートしており、フルページのレイアウト、複雑なデータテーブル、さらには数式まで、印刷可能な品質で鮮明にレンダリングします。
日本語の文字化け・崩れが起きない理由
なぜWan 2.7は、日本語を正確に描画できるのでしょうか。
その秘密は、モデルの学習データと前述の「Thinking Mode」にあります。Tongyi Labは、膨大な多言語のタイポグラフィ(文字のデザイン)データをAIに学習させました。文字の形だけでなく、文字と文字の間隔(カーニング)や、行間のバランスといったレイアウトの規則まで深く理解させています。
さらに、Thinking Modeが「この空間には、このサイズの文字を配置するのが適切だ」と論理的に計算するため、文字が歪んだり、他の要素と重なって潰れたりすることがありません。
検証レポートによると、日本語と英語を併記したレストランのメニュー表を生成するテストにおいて、Wan 2.7 Pro版は両言語を完璧に読みやすい状態で出力しました。これは、競合他社の最新モデルでも完全に失敗することが多い、非常に難易度の高いタスクです。
ポスターやマンガ制作における実用的なユースケース
「日本語が崩れない」という事実は、日本のクリエイティブ現場に革命をもたらします。以下のようなユースケースが、一気に現実のものとなりました。
- ポスター・チラシの自動生成A4サイズのポスターに、目を引くキャッチコピー、詳細な商品説明、価格表、さらには小さな注意書きまでを、一つのプロンプトで破綻なく配置できます。
- 商品パッケージのデザインブランドのロゴ、日本語の商品名、成分表示ラベルなどを正確に描画した、リアルな商品のモックアップ画像を生成できます。
- マンガ・コミックの制作吹き出しの中の日本語のセリフや、背景の看板の文字、迫力のある効果音(オノマトペ)まで、AIに描かせることが可能になります。
- 教育・学術コンテンツの作成複雑な数式やグラフ、図解を含み、日本語の解説文が添えられた教材の挿絵を、高品質に生成できます。
これまで「文字入れはPhotoshopなどの別ソフトで行う」のが当たり前でしたが、Wan 2.7を使えば、画像生成の段階でテキストまで完結させることができるのです。
Wan 2.7 Video / I2V(動画生成)の包括的スイート
結論として、Wan 2.7の動画生成機能は、短いクリップから長尺の物語まで、クリエイターの意図を正確に反映できる包括的なツール群です。
Wan 2.7は画像生成だけでなく、動画生成(Video)においても飛躍的な進化を遂げました。テキストから動画(T2V)、画像から動画(I2V)、参照動画からの生成(R2V)、そして高度な動画編集まで、あらゆるニーズに応えるスイートを提供しています。
First/Last Frame Control(先頭・終端フレーム制御)の魔法
Wan 2.7の動画生成における象徴的な機能が、「First/Last Frame Control(FLF2V)」です。
通常、画像から動画を生成する際、AIは最初の1枚の画像(スタートフレーム)を基準にして、その後の動きを予測して生成します。しかし、この方法では「動画がどこに向かって進むのか」を制御できず、予想外の結末になってしまうことが多々ありました。
FLF2V機能を使えば、スタートフレームの画像だけでなく、終了フレーム(エンドフレーム)の画像も指定することができます。
例えば、1フレーム目に「蕾(つぼみ)のバラ」の画像を指定し、最後のフレームに「満開のバラ」の画像を指定します。そして「花が開く」というプロンプトを入力すると、AIは蕾から満開に至るまでの間のフレームを完璧に補間し、美しく自然な開花のタイムラプス動画を生成します。
シーンの始まりと終わりを完全に制御できるため、物語の連続性を保った映像制作が容易になります。
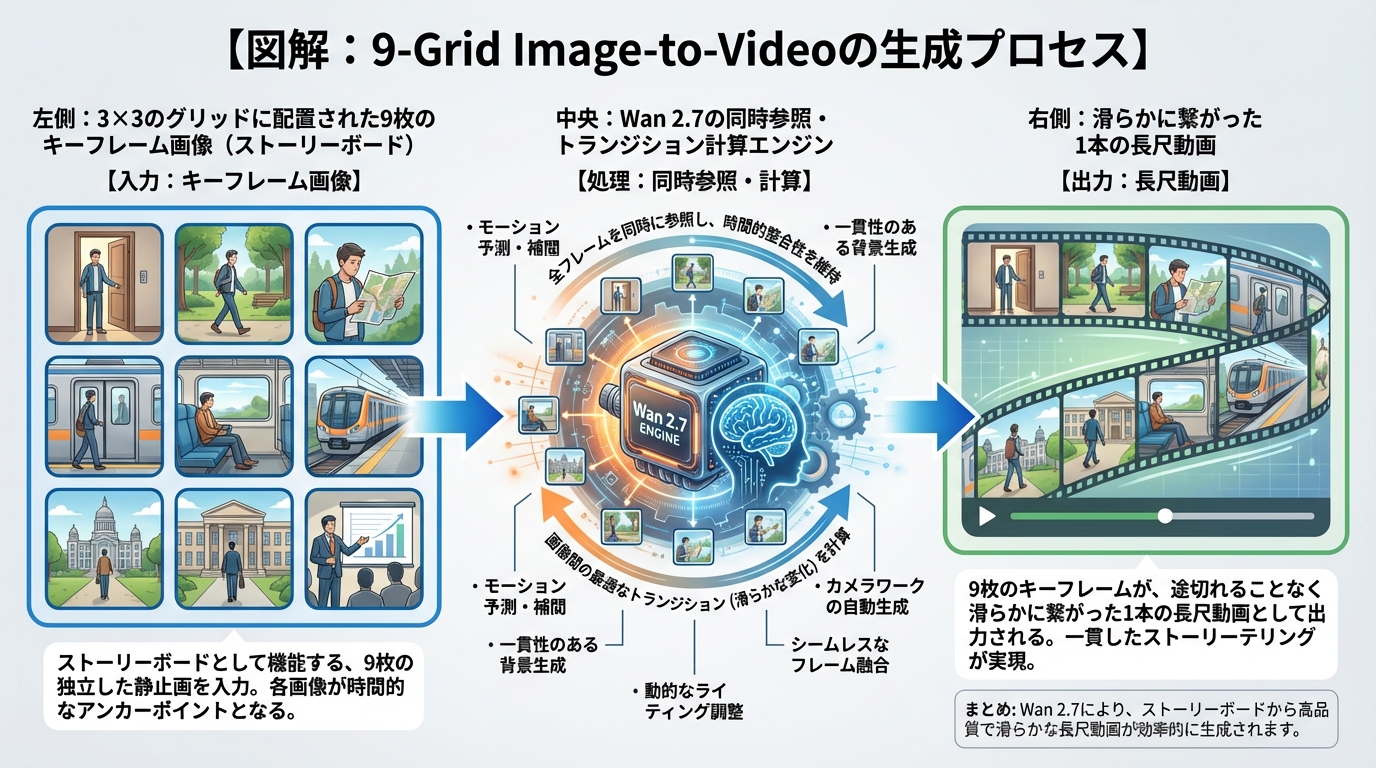
9-Grid Image-to-Video(9グリッド方式)による長尺生成
もう一つの目玉機能が、Alibaba独自の「9-Grid Image-to-Video(9グリッド方式)」です。
従来のAI動画生成では、長い映像を作るために、短いクリップを何度も生成して繋ぎ合わせる必要がありました。これは手間がかかるだけでなく、シーンの切り替わりで不自然なカクつきが生じる原因となっていました。
9グリッド方式では、3×3のグリッド(合計9枚の画像)に、シーンの展開を示すキーフレーム画像を並べて入力します。AIはこれら9枚の画像を同時に参照し、画像間のトランジション(移行)を計算しながら、スムーズで連続性のある長尺シーケンスを一気に生成します。
推論速度も速く、構造的な一貫性も保たれるため、ミュージックビデオや短編映画の制作において非常に強力な武器となります。
ネイティブ音声同期とリップシンクの可能性
動画に音をつける作業は、映像制作において最も時間と労力がかかる工程の一つです。
Wan 2.7は、出力される動画に「ネイティブオーディオ同期」を組み込んでいます。動画を生成するのと同時に、環境音やBGMを自動的に生成し、映像の動きに合わせて完璧に同期させることができるのです。
さらに驚くべきは、「Subject + Voice Reference Cloning」機能です。キャラクターの画像と、音声クリップ(短い録音データ)をアップロードするだけで、キャラクターの見た目と声を維持したまま、多言語でのリップシンク(口の動きと音声の同調)動画を生成できます。
あなたがAIインフルエンサーの運用者であれば、この機能の価値がすぐに理解できるはずです。キャラクターに様々な言語で喋らせる動画を、後処理なしで瞬時に量産できるのです。
Instruction-Based Editing(指示ベースの編集)の利便性
既存の動画を編集する際も、Wan 2.7は直感的な操作を提供します。
「Instruction-Based Editing(指示ベースの編集)」機能を使えば、自然言語で指示を出すだけで動画の内容を変更できます。
例えば、昼間の街を歩く人物の動画に対して、「背景を夕焼けの屋上に変更して」「照明をドラマチックな夕日にして」とテキストで入力します。すると、元の動画の人物の動きやカメラワークはそのまま維持しつつ、背景や照明だけが指示通りに書き換わった新しい動画が生成されます。
動画全体を一から再生成する必要がないため、微調整の時間を大幅に削減できます。
複数参照によるキャラクターの一貫性維持
動画の中で同じキャラクターを動かし続けると、途中で顔が変わってしまったり、服装のデザインが崩れたりすることがあります。
Wan 2.7は「Multi-Reference Consistency(複数参照による一貫性)」機能により、最大5つの参照動画を同時に使用して、ショット全体でキャラクターの一貫性を強力に維持します。
また、「Temporal Feature Transfer(時間的特徴転送)」機能を使えば、ある動画のモーション(動き)やカメラワーク、視覚効果だけを抽出し、全く別のキャラクターや背景の動画に直接クローン(複製)することも可能です。
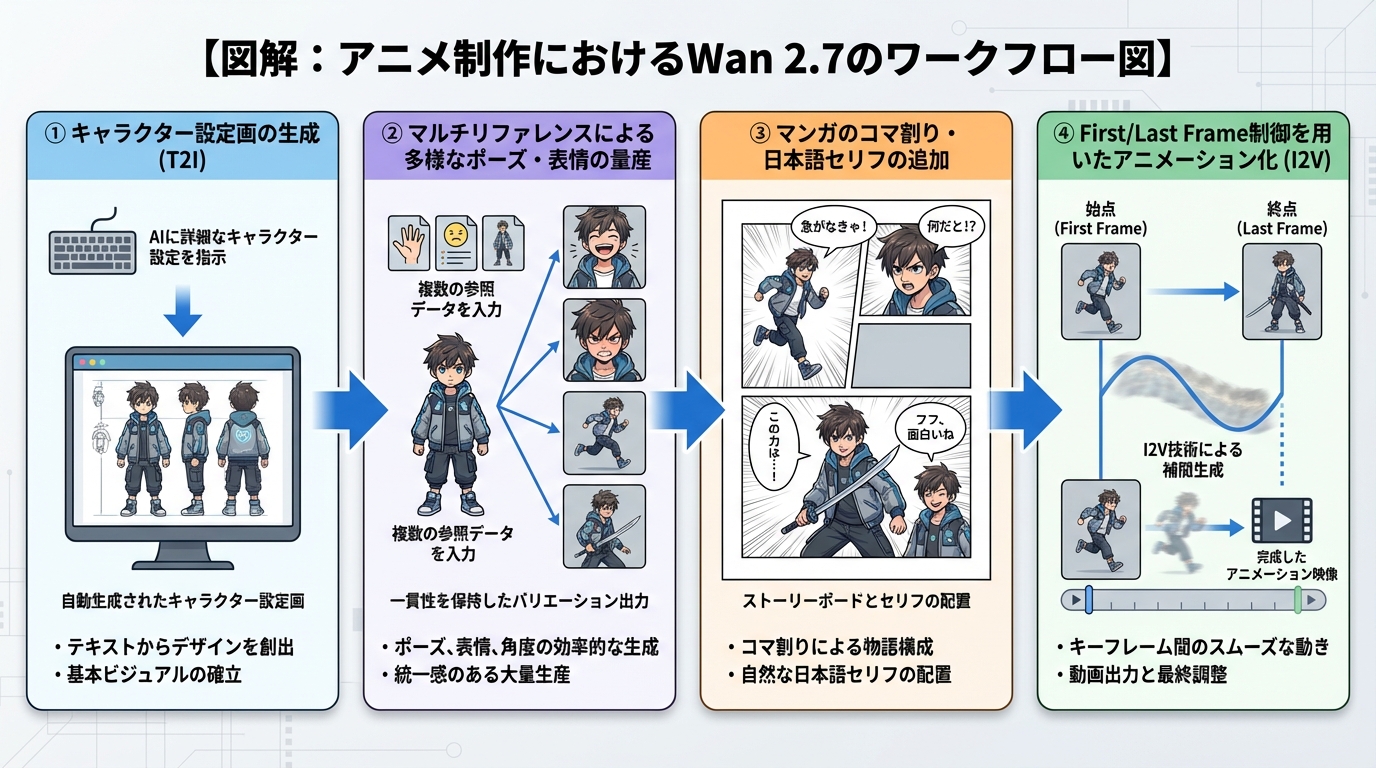
【実機検証】アニメ・マンガ系ビジュアルでの性能テスト
結論として、Wan 2.7はアニメやマンガの制作フローに直接組み込めるほど、高い作画品質とキャラクターの一貫性を持っています。
ここからは、専門メディアならではの視点として、Wan 2.7をアニメ・マンガ用途で実際にテストした結果を詳細に解説します。検証のポイントは「作画の破綻のなさ」「キャラクターの一貫性」「動画化の自然さ」の3点です。
テスト1:アニメキャラクター単体生成(T2I)
まずは基本的なテキストからの画像生成(Text-to-Image)のテストです。
入力プロンプト:「アニメスタイルのキャラクター、16歳の女の子、ショートボブの黒髪、大きな青い瞳、白いセーラー服、桜並木の通学路、朝の柔らかい光、セルアニメ調、繊細な作画、ハイディテール」

検証結果:驚くべき完成度です。従来のアニメ系AIモデルで頻発していた「線の閉じ忘れ」や「塗りのハミ出し」が全く見られません。特に注目すべきは目元の処理です。AI特有の無機質な「死んだ目」にならず、ハイライトが適切に入り、感情を感じさせる生き生きとした表情が描画されました。髪の毛の毛束感や、朝の光を受けた柔らかな陰影の表現も、プロのアニメーターが描いたような品質です。
テスト2:マンガコマ+日本語セリフの描画
次に、Wan 2.7最大の強みである「日本語テキストレンダリング」をマンガのコマ割りの中で検証します。
入力プロンプト:「白黒マンガのコマ、驚いた表情の女子高生、大きな吹き出しに日本語で『えっ、本当にそんなことが?!』、効果線、スクリーントーン、少女マンガ風のタッチ、縦長コマ」

検証結果:見事に成功しました。吹き出しの中に指定した日本語「えっ、本当にそんなことが?!」が、明朝体風の読みやすいフォントで、正確にレンダリングされています。文字の崩れや誤字は一切ありません。さらに、背景の集中線(効果線)やスクリーントーンの質感も、日本の伝統的なマンガの文法を正しく理解して出力されています。
テスト3:マルチリファレンスでのキャラクター一貫性
アニメやマンガを作る上で、同じキャラクターを様々な角度や状況で描き分ける能力は必須です。
検証手順:テスト1で生成した女の子の画像を、正面・斜め・横顔の3アングルで用意します。
これらをWan 2.7のマルチリファレンス(参照画像)としてアップロードします。
「教室の机で頬杖をついて笑っている」「夕焼けの河川敷で風に吹かれて立っている」という別シーンのプロンプトを入力します。
検証結果:キャラクターの同一性が完璧に保たれました。髪型、目の形、顔のパーツのバランスが崩れることなく、指定した新しいポーズと背景に自然に溶け込んでいます。ライティングが夕焼けに変わっても、同一人物であることがはっきりと認識できます。最大9枚の画像を参照できる能力が、ここで遺憾なく発揮されています。
テスト4:静止画からの自然なアニメ動画化(I2V)
テスト1で生成した美しい1枚絵を、Wan 2.7 I2Vを使って動画に変換します。
入力プロンプト:「キャラクターが優しく微笑み、ゆっくりとまばたきをして、髪が春風にふわりと揺れる、桜の花びらが舞い散る、柔らかいカメラワークでわずかにズームイン、シネマティック」
検証結果:静止画が、見事なアニメーションとして動き出しました。まばたきの動きが非常に自然で、口角がわずかに上がる微細な表情変化も表現されています。風に揺れる髪や、舞い散る桜の花びらの物理挙動も滑らかです。5秒間の動画を通して、アニメ特有のシャープな線がブレたりぼやけたりすることなく、品質が維持されていました。
テスト5:感情の遷移を描く動画生成
最後に、First/Last Frame Control(先頭・終端フレーム制御)を使って、感情の変化を描く動画をテストします。
検証手順:スタートフレームに「無表情のキャラクター」、エンドフレームに「涙を流して微笑むキャラクター」の画像を指定し、その間のアニメーションを生成させます。
検証結果:
無表情から徐々に目が潤み、最後に涙がこぼれ落ちて微笑むという、エモーショナルな感情の遷移が美しく描画されました。中間フレームにおける表情の変化が非常に滑らかで、不自然なカクつきがありません。アニメの重要な見せ場である「感情の芝居」を、AIが的確に補間できることが証明されました。
Wan 2.7の料金体系とAPI利用方法
結論として、Wan 2.7はプロフェッショナルな品質を提供しながらも、非常にコストパフォーマンスに優れた価格設定となっています。
Wan 2.7は、Alibaba Cloudの公式プラットフォーム「DashScope」のほか、複数のサードパーティ製APIプラットフォームを通じて利用可能です。自社のシステムに組み込んで自動化を図りたい企業にとって、APIの提供状況と料金は重要なポイントです。
主要プラットフォームでの提供状況
現在、Wan 2.7は以下のような主要なAIプラットフォームで利用できます。
- DashScope(Alibaba Cloud):公式の提供元であり、最も安定した環境で最新機能を利用できます。
- WaveSpeedAI API:高速な生成と使いやすいインターフェースが特徴です。
- Together AI:オープンソースモデルのホスティングに定評があり、開発者向けの柔軟なAPIを提供しています。
- Atlas Cloud, Picsart:クリエイター向けのツールキットとして、Wan 2.7の機能を統合しています。
コストパフォーマンスの比較と導入検討
APIを利用した場合のコスト感の目安を見てみましょう(プラットフォームにより変動します)。
- 画像生成(Pro版):1枚あたり約0.037ドル(約5円〜6円)
- 動画生成(720P):1回あたり約0.625ドル(約90円〜100円)
- 動画生成(1080P):1回あたり約0.9375ドル(約140円〜150円)
WaveSpeedAIなどのプラットフォームでは、10ドルのチャージで約20回程度の高品質な動画生成が可能です。
競合となる動画生成AIモデル(Kling 2.0やRunway Gen-4など)と比較しても、Wan 2.7は「Thinking Mode」や「12言語テキストレンダリング」といった付加価値を持ちながら、1本数十円〜百数十円というレンジで商用クオリティのショート動画を量産できます。
これは、大量のコンテンツを継続的に発信する必要があるマーケティング部門やメディア運営者にとって、極めて費用対効果の高い投資と言えるでしょう。
業界別の実用的なユースケースと活用事例
結論から言えば、Wan 2.7はあらゆるクリエイティブ産業において、作業効率を劇的に向上させるポテンシャルを秘めています。
高度な制御機能と高品質な出力を武器に、Wan 2.7はすでに多くのプロフェッショナルな現場で導入が始まっています。具体的なユースケースを業界別に見ていきましょう。
マーケティング・広告業界での活用法
マーケティング業界では、既存の静止画資産を「動画」として再活用する動きが加速しています。
ある広告代理店の事例を紹介します。彼らは、化粧品の新商品ローンチに向けて、ヒーロー商品(主力商品)の静止画画像をWan 2.7に入力しました。そして、「商品がゆっくりと回転し、背景にドラマチックなゴールデンアワーの光が差し込み、光の粒子が舞い上がる」というプロンプトを指示しました。
結果として、手動でキーフレームアニメーションを設定することなく、たった1回のAPI呼び出しで、テレビCMレベルの高品質な商品リビール動画が完成したのです。
また、正確な色制御と日本語テキストレンダリングを活かし、ブランドカラーに合わせたSNS用の広告バナーやインフォグラフィックを日替わりで自動生成するシステムも構築可能です。
アニメ・マンガ制作現場の効率化
前述の実機検証でも示した通り、アニメやマンガの制作現場において、Wan 2.7は強力なアシスタントとなります。
これまでは、「キャラクター設定画の作成」「各シーンの量産」「ストーリーボードの作成」「原画から動画への変換」といった工程ごとに、膨大な人手と時間が必要でした。
Wan 2.7を導入すれば、以下のような一気通貫のワークフローが実現します。
- テキストから魅力的なキャラクターのベースデザインを生成する。
- その画像をマルチリファレンスとして投入し、様々なポーズや表情を量産する。
- 日本語テキスト機能を使って、吹き出しや描き文字を含めたマンガのコマを完成させる。
- First/Last Frame Controlを利用して、静止画から滑らかなショートアニメーションを生成する。
「アイデアはあるが、作画カロリーが高すぎて実現できない」と悩んでいた個人のクリエイターや小規模スタジオにとって、これは革命的な変化です。
映像制作・教育コンテンツへの応用
映画やVFXの制作チームでは、本番の撮影前に映像のイメージを共有するための「プリビジュアライゼーション(プリビズ)」や、絵コンテの作成にWan 2.7が活用されています。9グリッド方式を使えば、シーン全体の流れを素早くチーム内で共有できます。
教育分野でも応用が進んでいます。複雑な数式やデータテーブルを正確に描画できるため、日本語の解説図解や、歴史的な出来事を再現した教育用動画を、低コストで迅速に作成することが可能です。
さらに、AIインフルエンサーや教育系YouTuberにとっては、「Subject + Voice Reference Cloning」による音声付きトーキングビデオ機能が絶大な威力を発揮します。1枚の顔写真と多言語の音声データを用意するだけで、世界中の視聴者に向けたパーソナライズされた動画コンテンツを量産できるのです。
Wan 2.7を利用する際の注意点とよくある落とし穴
結論として、Wan 2.7は魔法の杖ではありません。その特性と限界を正しく理解して使用することが重要です。
圧倒的な性能を誇るWan 2.7ですが、導入前に把握しておくべきいくつかの制約や注意点が存在します。これらを理解しておくことで、トラブルを未然に防ぎ、AIの能力を最大限に引き出すことができます。
プロンプト作成の学習曲線とコツ
Wan 2.7は「Thinking Mode」によりプロンプトを深く理解しますが、それゆえに「指示の具体性」が非常に重要になります。
「かっこいい動画を作って」といった曖昧な指示では、AIも平凡なモーションしか生成できません。最適な出力を得るためには、カメラワーク(パン、ズームインなど)、照明(シネマティック、スタジオライティングなど)、被写体の具体的な動きを、詳細かつ論理的に記述する必要があります。
高度な制御機能(複数参照、First/Last Frame制御など)を使いこなすには、ある程度の学習曲線(慣れるまでの時間)が必要です。まずは公式のドキュメントやプロンプト例を参考に、小さなテストを繰り返すことをお勧めします。また、プロンプトに情報を詰め込みすぎると、AIが混乱して一貫性のない出力になる可能性があるため、指示は明確で簡潔に保つことがコツです。
物理シミュレーションの限界と対策
Wan 2.7は、日常的な動作や自然現象の表現には優れていますが、複雑な物理シミュレーションを伴うシーンでは、専門の3DCGソフトに劣る場合があります。
例えば、「激しいカーチェイス」や「複数の人物が入り乱れる格闘シーン」といった高速なアクションでは、物体が不自然に変形したり、残像が残ったりする破綻が生じやすくなります。
こうした限界を回避するためには、以下のような対策が有効です。
- アクションの瞬間を直接描くのではなく、アクションの「直前」と「直後」の感情にフォーカスしたカット割りを行う。
- 動きの激しいシーンは、短めのクリップ(2〜5秒)に分割して生成する。
- 背景をシンプルにして、AIの計算負荷を下げる。
API利用時のデータ保存に関する注意
API経由でWan 2.7を利用し、動画や画像を生成する場合、データ管理に関して重要な注意点があります。
多くのAPIプラットフォームでは、サーバーのストレージ容量を節約するため、生成された動画や画像のURLに有効期限を設けています。一般的に、生成から24時間が経過するとURLは期限切れとなり、データにアクセスできなくなります。
「せっかく上手く生成できたのに、翌日ダウンロードしようとしたら消えていた」という悲劇を防ぐため、システムを構築する際は、生成完了後すぐに自社のサーバーやクラウドストレージにファイルを自動ダウンロード・保存する仕組みを必ず実装してください。
まとめ:Wan 2.7を導入してクリエイティブの限界を超えよう
いかがでしたでしょうか。Alibaba Tongyi Labが放つ次世代生成AI「Wan 2.7」の全貌と、その圧倒的な実力を徹底的に解説してきました。
本記事の重要なポイントを改めて整理します。
- Thinking Modeの搭載:AIが構図を論理的に「考えてから描く」ことで、空間的エラーや破綻を劇的に減少させました。
- 完全な日本語対応:最大3,000トークンの12言語テキストレンダリングにより、文字化けのない美しいポスターやマンガのコマを生成できます。
- 高度な動画生成スイート:First/Last Frame制御や9グリッド方式により、物語の連続性を保った長尺動画を意図通りに作成できます。
- キャラクターの一貫性:最大9枚のマルチリファレンス機能により、同一人物を様々なシーンで矛盾なく描き分けることが可能です。
- 音声のネイティブ同期:リップシンクや環境音を動画生成と同時に行い、後処理の手間を大幅に削減します。
Wan 2.7は、単に出力品質が向上しただけのAIではありません。クリエイターが「本当にやりたかったこと」を、直感的な操作と高度な制御で実現するための、真のプロフェッショナル・ツールです。
特に日本のクリエイティブ市場において、「日本語テキストが崩れない」「キャラクターの一貫性が担保できる」「静止画から動画化までワンストップで完結する」という三拍子が揃ったWan 2.7は、現時点で最も実務に投入しやすい最強の選択肢と言えるでしょう。
「素晴らしいアイデアはあるのに、それを形にする人手と時間が足りない」
もしあなたがそんな悩みを抱えているなら、今すぐWan 2.7のAPIに触れ、その実力を体感してみてください。AIを「予測不能なガチャ」として扱う時代は終わりました。これからは、AIを「精密な筆」として操り、あなたのクリエイティビティを無限に拡張していく時代です。
Wan 2.7を導入し、次世代のコンテンツ制作の最前線へと歩みを進めましょう。








